
One year ago, in my first article about OpenAI Whisper I made a prediction: I still think that one day we will have LLMs in the capability range between GPT-3 and GPT-3.5 (maybe up to GPT-4) – on our mobile devices. Now, let’s see how good the sentence has aged and how far we have come.
Before getting too excited, it should be made clear that no smartphone currently has a GPT-3.5 local model, which would still be quite remarkable. However, significant progress has been made towards this goal. The models have improved significantly, with Llama 2 being a major breakthrough in the summer of 2023. Mistral and Mixtral have further solidified the foundation for open-source LLMs. Additionally, the continuous optimization of this technology has led to the development of Ollama. Ollama is currently the easiest way to try out LLMs on your own computer, providing access to a variety of LLMs that can run on a moderate machine. That’s leaves us with the questions which LLM is suited best for our needs.
Let’s build the Benchmark!
One needs to know the performance differences between changes when building an RAG application or anything beyond a simple Prompt interface. We have metrics like speed, memory consumption and many more in the classical software engineering. But when working with LLMs you have a new strange one: answer quality.
My particular problem was the answer language consistency. As a tech-savvy person, I use English on a daily basis for my work. Less tech-savvy persons are often limited to their native language. A big advantage of ChatGPT at the time was that it already had a very good multilingual capability. This lowers the barrier to entry if you don’t have to switch languages. So, if I want to recommend the local LLMs in the private and business sector, I have to ensure that the LLM can answer in the local language.
At is core, it is a pretty interesting task. Most modern LLMs are trained on a large, unsupervised corpus of English text. Many modern smaller open source LLMs are trained using English at is core language. Multilingual capabilities still somehow develop.
Building the Benchmark
Fifty general questions were prepared for the various LLMs to answer. All questions are in German, but it is not explicitly stated that the answers must also be in German. The model itself should simply follow the source language. Due to the large number of answers and tested models (20 in total), I opted not to conduct the evaluation myself and instead used a little trick. There are models that are very good at detecting the language of a sentence. In my case, I am using xlm-roberta-base-language-detection from HuggingFace.
However, this is where the escalation spiral began. At first, I wanted to test only models with up to about 3 billion parameters. But what about a comparison with models with 7 billion parameters? What about closed source models like GPT-3.5 and others? And while we’re at it, how can you test the language without checking the content? It is possible that an LLM speaks German but talks nonsense. Something that one would technically predict under the given circumstance. So the answers had to be checked.
Here comes the next trick into play. Most of the LLMs I wanted to test still had weaknesses. This is known from the English benchmarks. So we can just use a smarter LLM for evaluating the content. Initially, my first approach was to use only GPT-4 as the evaluation model. But after including GPT-3.5 and GPT-4 in the suite of tested models, several evaluation models were required to avoid self-evaluation by the teacher. The advantage here is that there are now several models that are like GPT-4, namely Claude 3 Sonnet and Mistral Large.
In the end, each of the 20 LLMs were evaluated by 3 LLMs.
Model selection
| Open Source | tinyllama (1B), stablelm2 (2B), phi-2 (3B), gemma-2b (3B), llama2 (7B), mistral (7B), gemma (9B), open-mixtral-8x7b (47B) |
| Fine Tuned | orca-mini (LLama, 3B), mistral-openorca (Mistral, 7B), nous-hermes2 (Llama 2, 11B), dolphin-mistral (Mistral, 7B), openhermes (Mistral, 7B), neural-chat (Mistral, 7B) |
| Closed Source | claude-3-haiku, claude-3-sonnet, gpt-3.5-turbo-0125, gpt-4-0125-preview, mistral-large-latest, mistral-small-latest |
All open-source models (except Mixtral, which was unfortunately too large) were tested using Ollama on an RTX 2060 with 6 GB of VRAM, while the closed-source models were used with their respective providers (except Claude, which was used via AWS). The responses were generated and evaluated using GPT-4 Turbo, Claude 3 Sonnet, and Mistral Large in their newest editions. The time taken to answer all 50 questions was also recorded.
Checking the quality of responses
For each answer, a evaluation JSON object was created. Points were awarded on a scale from „excellent“ to „insufficient“ for
- accuracy (Is the answer factually correct and relevant to the question?),
- linguistic quality (How good is the grammar, syntax, and spelling in the answer?),
- contextual sensitivity (Does the model demonstrate a good understanding of the question’s context? Is it able to switch between different contexts and respond appropriately?)
- comprehensiveness (Does the answer cover all aspects of the question, provide relevant information, and is it thorough without being digressive or irrelevant?)
The results were converted into numerical grades from 1 (best) to 6 (worst). In a second step, each generated sentence was checked for its language, resulting in a ratio of how many sentences were in German, English, or another language.
Technically, this step was not 100% clean, as I used simple sentence splitting as the separation system. Enumerations or other stylistic elements were unfortunately sometimes classified as separate sentences during the process, leading to noise in the results. Many different languages occurred only once each. Therefore, even with a perfect answer in the target language, 100% accuracy cannot be achieved. These results should not be taken too literally. Now, let’s move on to the results.
Language

Phi and Llama 2 models have a preference for responding in English, while Mistral has a slight bias towards English with a 60% preference. It is interesting to note that none of these models were explicitly trained on German. Similarly, Gemma was not trained on German, but its larger embedding space and more tokens may explain its good performance. Stablelm 2, on the other hand, was explicitly trained on multiple languages, including German, which explains its excellent results. It is possible that Mixtral’s size allows it to perform well in German.
The fascinating thing is that the number of parameters has nothing to do with the language. Whether the response is in the same language depends on the data.

This is further evident when examining fine tuning. The average performance of all models has significantly improved, except for the Orca Mini, which is still based on the Llama 1 in the 3B variant.

The situation is similar with the closed source models. Everywhere you get an answer in German.
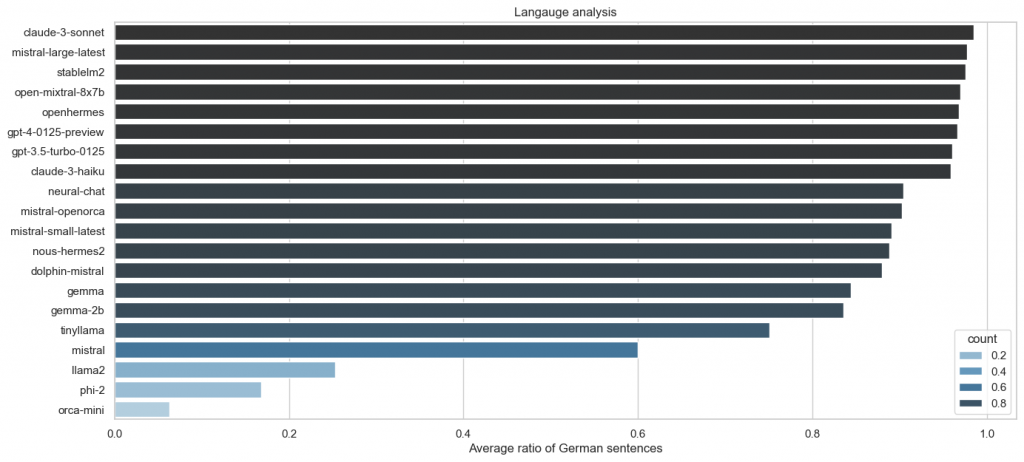
When examining models such as StableLM 2, it is evident that data plays a crucial role in their success. It is important to note that this chart should not be viewed as a definitive ranking due to the presence of noise.
Content
What about the content of the answers? Let’s start again with the open-source models:
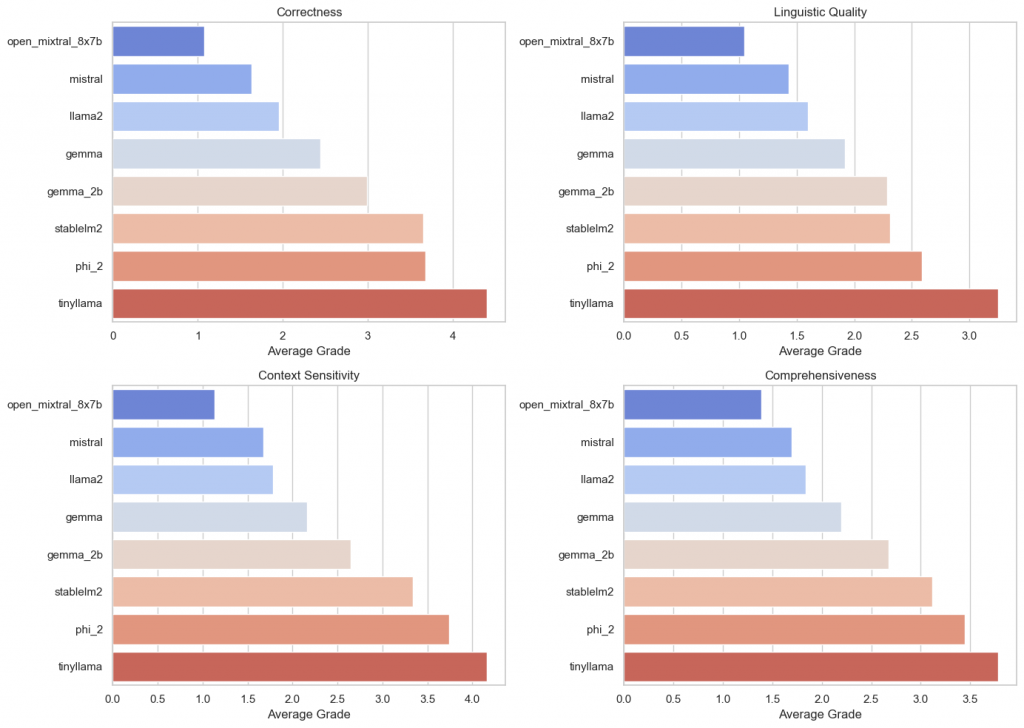
- The more parameters, the better the answers. The smallest models perform the worst. This is to be expected as there is a factor of 3 between 7B and 2B. Nevertheless, the difference between the worst model 7B and the best model 2B is not very large.
- As the answer gets better, the quality of the language improves in the same ratio. There is no dumb answer that is linguistically perfect. The order between the different categories is almost identical.
- The data also plays an important role. Although Llama 2, Mistral, and Gemma are similar in size, they have very different results.
- The jump to 47B is also not very large in this case. Mistral 7B achieves an average score of 2 when it comes to answer accuracy.
How let’s look at the fine-tuned models
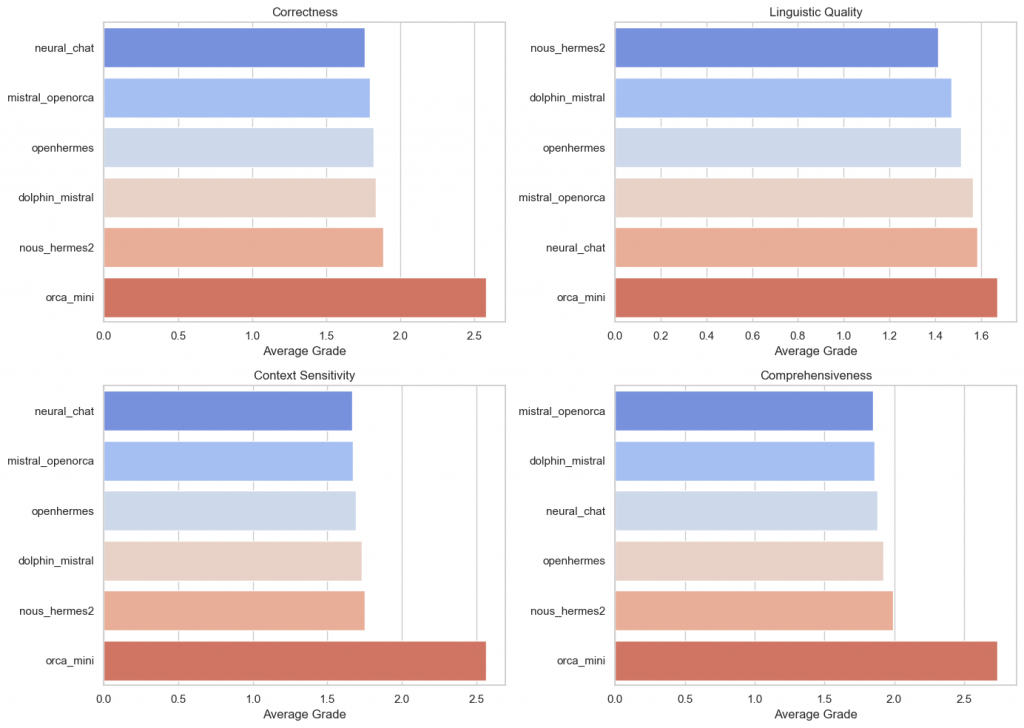
Some observations:
- Fine-tuning of models usually only changes performance marginally.
- This means that, for example, sentence structure can be improved, but not the content.

A direct comparison with the base model 7B shows that fine-tuning is not necessarily required when answering general questions. The performance of the base model has not been significantly improved. However, considering the language consistency evaluation, it may aid in enhancing the consistency of the response. In particular, Llama 2 has received a boost in speech evaluation through fine tuning, but less in the quality of the answer.
Close Source LLMs
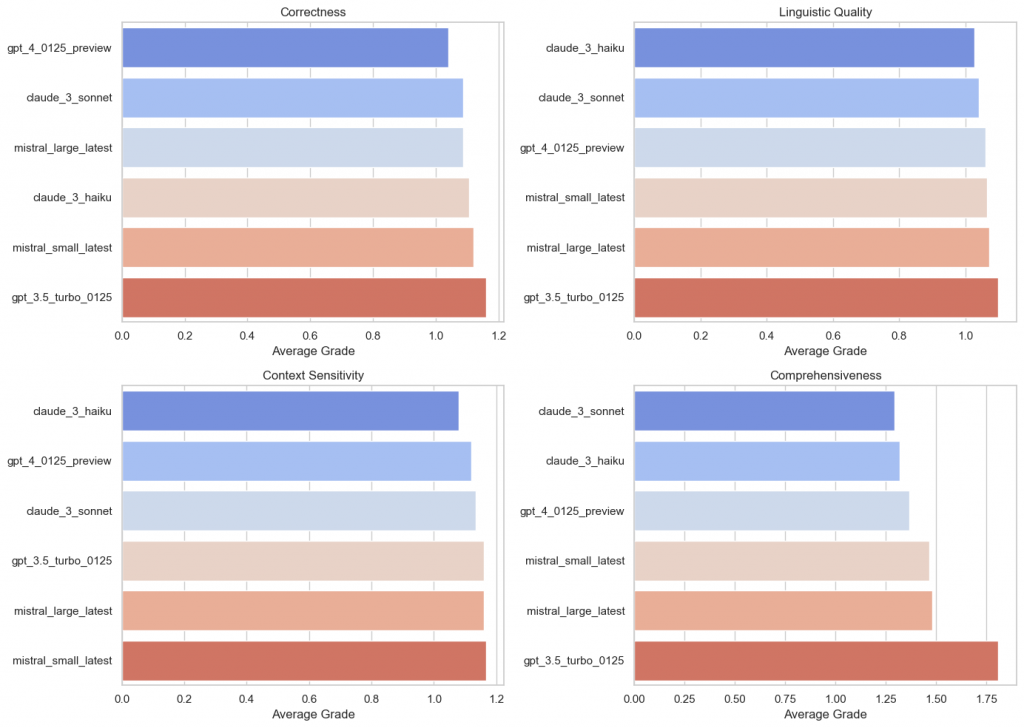
The closed-source models are not much different when it comes to their performance results. The response quality is usually very high.
All in all, the following picture emerges:
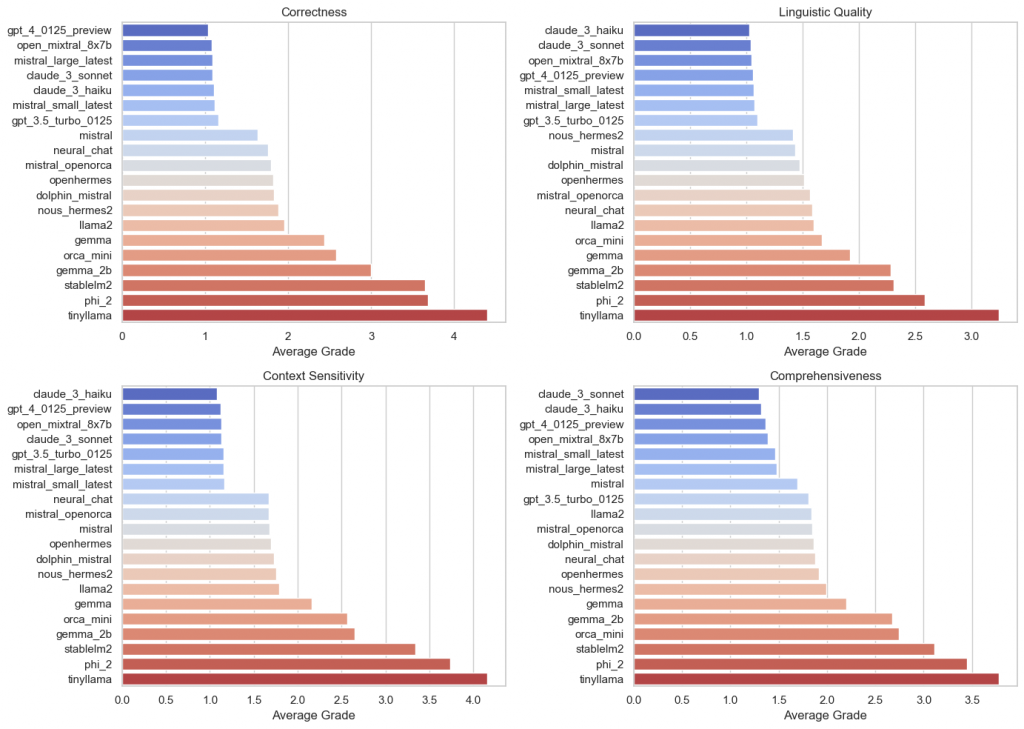
Here, the results are grouped according to the valuation model used:
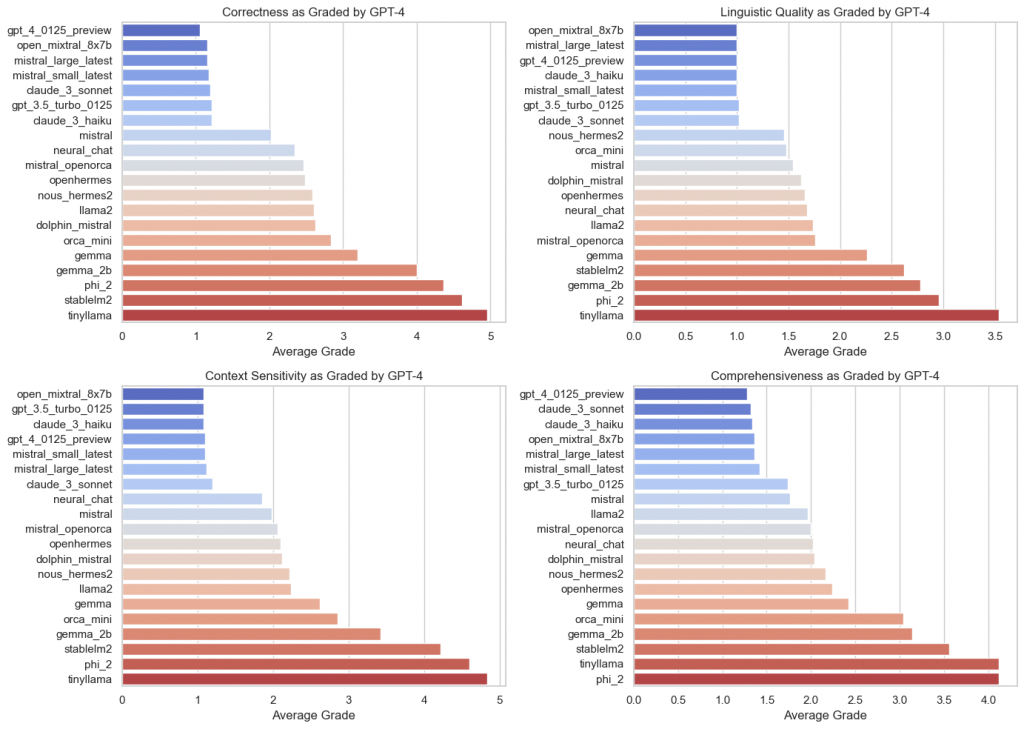
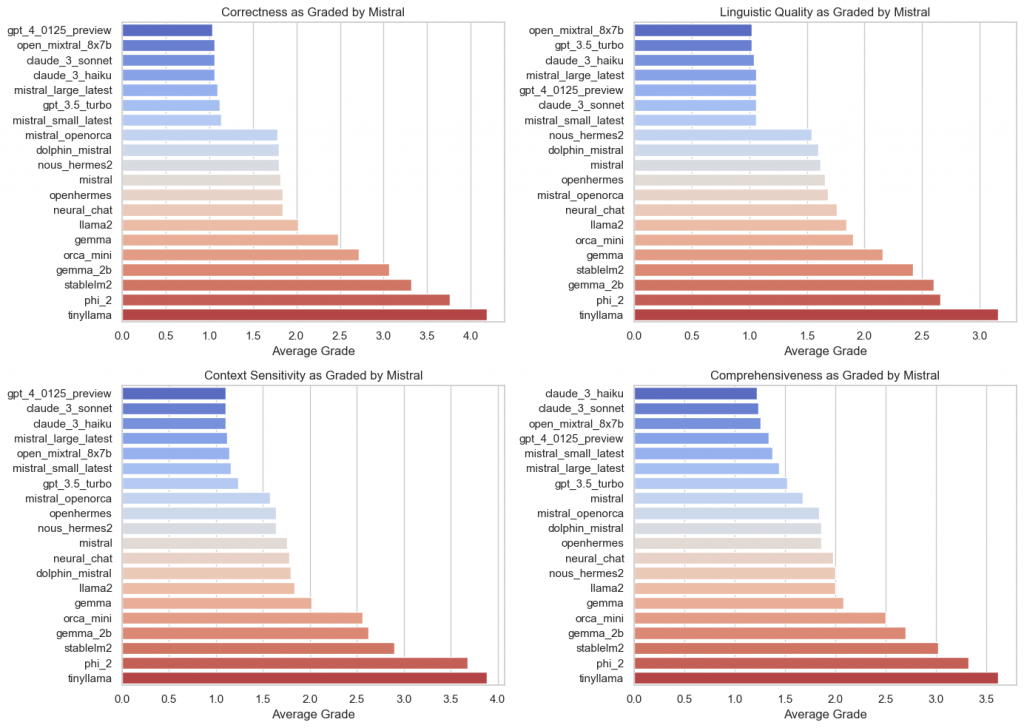

A brief look at time
It is also interesting to take a look at the time. This was measured for all 50 answers. This means that it can be seen as a bit of an average. At the same time, individual anomalies, such as a very slow generation of a response, can distort the overall result a little. Also because local hardware was used, a distinction must be made between the Ollama and Cloud models. Let’s start with the cloud:
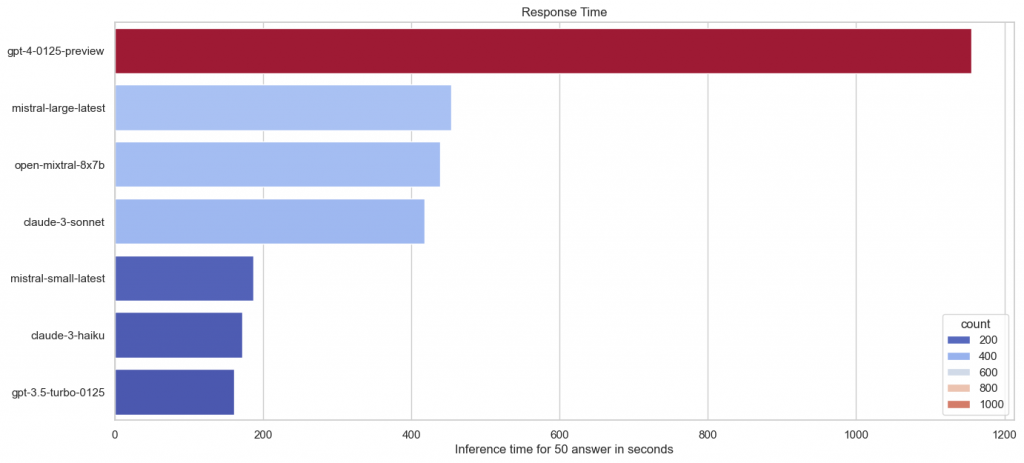
Can we take a moment to talk about the fact that GPT-4 is 2.5 times slower than the competition for some reason? This is something I can very strongly confirm from my own experience. For this experiment, each answer had to be checked by 3 models. Claude and Mistral had finished similarly quickly, GPT-4 took ages. It’s something that should definitely be a priority for the next generation of models.
But otherwise you can recognize a few groups. Mistral small, Claude 3 Haiku and GPT-3.5 are similarly fast. Claude 3 Sonnet and Mistral Large are fast, too. Especially for Claude 3 Haiku I find it a very impressive performance, as in some benchmarks it approaches GPT-4 in answer quality.
Local LLMs
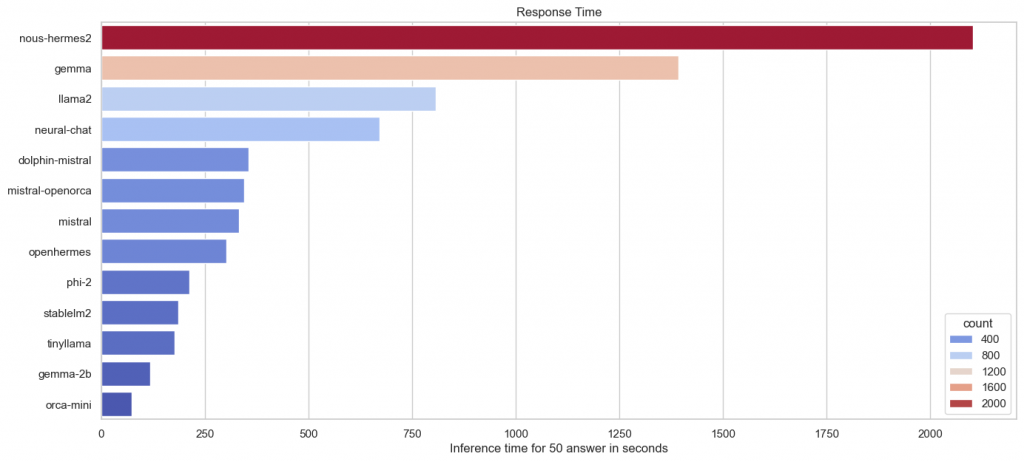
Let’s move on to the open LLMs. Nous Hermes 2 was identified as an outlier due to its size exceeding the capacity of the GPU (RTX 2060, 6 GB VRAM). As a result, the CPU had to be utilized, which significantly impacted performance. Once again, this proves the great importance of GPUs.
The time also increases with the number of parameters, but optimization also plays an important role. There is no other way to explain why Mistral and the associated models perform so well. Llama 2 and Gemma still need a lot of optimization in this area. There are similarly wild results for the small models with few parameters. Gemma-2b is the largest in this class, but is one of the fastest.
On the other hand, it must also be said that the data only comes from one run. Perhaps the inference times of the models at Ollama are very different, which can lead to these differences.
Conclusion
So, what can we take away from all these results? One of the most fascinating findings was that the language used does not necessarily have to be related to the content. Even if the answers were in English, they were still correct in terms of content, despite the question being in German. There is already some research in this area, as shown in this paper. In summary, the LLM operates within a conceptual space (that tend to be structured around the English language). The final answer is only converted into the target language at the end. Although there may be instances where this conversion does not occur, the content remains accurate in the concept space and is typically translated into English. That also explains why fine-tuning can help in this case. It doesn’t require major changes to trigger this translation process.
Multilingualism is already covered in most of the usual benchmarks today. MMLU and other benchmarks are examples of this. However, I wanted to have a closer look at the exact numbers myself. This topic is not unimportant. When working with SMEs in a more rural area, it’s important to keep in mind that they are far from the big cities and their internationality. In such areas, you can’t assume an understanding of the English language, especially when it comes to a new and unfamiliar technology. The answer has to come as expected, and that unfortunately means it has to be in the same language.
The perfect moment
This is why I appreciate the release of OpenAI ChatGPT. It met the necessary criterion at the time of its release. For a long time, GPT-3.5 and GPT-4 were some of the only valid options when multilingualism was a topic. That changed significantly in the last year, along with the higher quality of the answers.
An LLM must also be able to handle specific knowledge for such a use case. The questions posed to the LLMs could have been written by a German teacher with a fondness for quiz shows, which is not unexpected. The sweet spot for this was GPT-3.5, as confirmed by the data above, where we almost have a perfect result from this model level.
I am aware that some people have already dismissed this level of performance. We discuss more about which LLM can write better code or reason. But especially for the smaller models, this is still a big challenge. There was a focus on the „small“ models in this experiment because an SME certainly does not have the money for an H100. Therefore, inference time and resource consumption were two metrics that I did not want to ignore.
Old and new problems
It was also a lesson to run all these benchmarks and collect the data. On paper, I had known for a long time that one could use GPT-4-like LLMs as evaluation modules, but I didn’t know how laborious it would be. In the end, it was easier than expected, but not without its own problems. The consistency of the results from Claude, Sonnet, GPT-4, and Mistral Large is still lacking. For the evaluation, except for Claude, the JSON mode was activated and a fixed JSON structure was provided. But as it always is with prompting, it is sometimes only taken as an ignorable recommendation by the model and breaks the data pipeline.
So, it still means that sometimes the data has to be manually formatted. We didn’t have many requests here but there were outliers among less than 100 results. And here we see the discrepancy between research and product development. The more complex the task becomes, the more chaotic the quality. Some people forget this when it comes to LLMs.
Opinion
But even if you have perfected the prompts, it doesn’t mean you are safe forever. This primarily concerns the closed-source models and is inherent in the nature of the services. What is the true offering of LLM operators such as OpenAI, Claude, and Google? In practice, users submit a request, similar to search engines, and receive the most suitable answer. The quality is variable, and usually, some adjustments are given to the user in the form of different models to provide personalization options. But if one day OpenAI were to downgrade their GPT-4 option to the level of a BERT Transformer, users can do very little about it.
Of course, then no one would give OpenAI any more money, and big companies like Microsoft would exert a strong influence on OpenAI to reverse that decision. This is an extreme example, but it would be theoretically possible. The quality of the API is not necessarily guaranteed. So, if GPT-4 becomes worse, reads prompts differently, or proactively rejects requests, there is very little one can do to resist.
Each prompt wrapper is dependent on LLM providers success or failure. Precisely for this reason, as shown in this report, one of the most popular reasons for using open-source LLMs is control and adaptability. There is a good reason why several providers are being considered and used for enterprise products. You don’t want to be dependent on only one supplier. This is where I see the strength of open source.
New models
So, it was all the more encouraging to hear the news earlier this year when other providers like Google, Mistral, and Claude introduced models similar in strength to OpenAI’s. At present, there is a choice and the monopoly on quality by GPT-4 has been somewhat disrupted. Of course, none of these models of this class are open source because it is still too lucrative to offer this technology freely.
There is also the possibility of a GPT-5 in the near future that is expected to outshine everything. But one should not count their chickens before they hatch. OpenAI has a significant concentration of know-how, computing power, market power, and partly financial resources that enable them to deliver great products. But this call for GPT-5 reminds me a little of the same call for Google when ChatGPT was first introduced. Even with the best conditions, market leadership in LLM products is not guaranteed unless it is put into application. As with Google, the public pressure on OpenAI is undeniable high. They are no longer just a good research group from Silicon Valley, but one of the most significant companies currently, even if OpenAI still has its own struggles with it.
Closing words
So, what is the state of the models and my prognosis from the beginning? Well, one year later, the commercial market has caught up to the level of GPT-4. At the same time, open models are gradually reaching the level of GPT-3.5, but not on mobile devices. But honestly, it’s just a matter of time, optimization, and hardware. The implementation of this technology is expected to be the focus of the upcoming year. It is important to note that despite its unconventional nature, many individuals outside of technology space have yet to experience significant advancements over the standard ChatGPT. This is also applicable to individuals who have not yet tried LLMs.
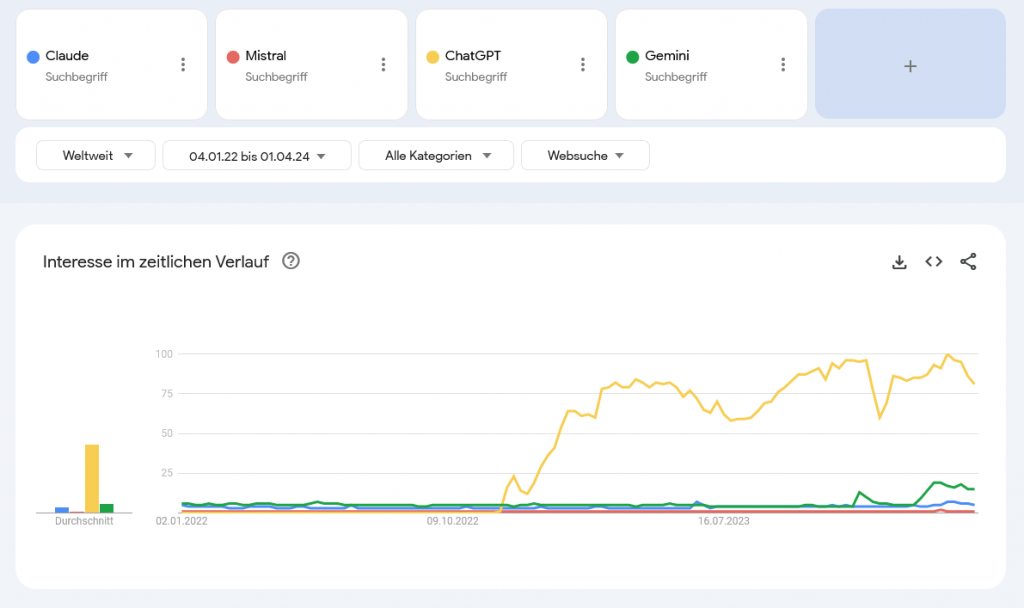
Many people simply do not use GPT-4 because it is only available as a subscription. In enthusiast communities, there are debates about which model is truly better in certain edge cases, but the outside world is not aware of the problems behind it. There was a small chance for a collapsing AI market if OpenAI had completely lost its way in November of last year. Much of the gains from last year only exists on paper and have not yet arrived in reality. Their trial is still pending. The story is just beginning.
Schreibe einen Kommentar